二十多年了, 由于实现的复杂性,很少有开发人员和架构师敢接触大数据系统, 对有能力的工程师要求过高, 冗长的开发时间, 以及关键架构组件的不可用性.
但近年来,新出现 big data 技术的发展使得大数据架构的数量出现了真正的爆炸式增长,这些架构每秒可以处理数十万甚至更多的事件. 没有周密的计划, 使用这些技术在执行和维护方面可能需要大量的开发工作. Fortunately, 今天的解决方案使得任何规模的团队都可以相对简单地有效地使用这些架构部分.
Period
Characterized by
Description
2000-2007
SQL数据库和批处理的流行
景观由MapReduce组成, FTP, 机械硬盘, 和互联网信息服务器.
2007-2014
社交媒体的兴起:Facebook、Twitter、LinkedIn和YouTube
通过日益普及的智能手机,照片和视频正在以前所未有的速度被创造和分享.
第一批云平台、NoSQL数据库和处理引擎(例如.g., Apache Cassandra 2008, Hadoop 2006, MongoDB 2009, Apache Kafka 2011, AWS 2006, 和Azure 2010)发布后,许多公司纷纷聘请工程师在虚拟化操作系统上支持这些技术, 大多数都是现场的.
2014-2020
Cloud expansion
较小的公司转向云平台, NoSQL databases, 处理引擎, 支持越来越多的应用程序.
2020-Present
Cloud evolution
大数据架构师将重点转向高可用性, replication, auto-scaling, resharding, load balancing, data encryption, reduced latency, compliance, fault tolerance, and auto-recovery. 容器、微服务和敏捷流程的使用继续加速.
现代架构师必须在使用开源工具开发自己的平台或选择供应商提供的解决方案之间做出选择. 在采用开源产品时需要基础设施即服务(IaaS),因为IaaS为虚拟机和网络提供了基本组件, 允许工程团队灵活地设计他们的体系结构. Alternatively, 供应商的预先打包解决方案和平台即服务(PaaS)产品消除了收集这些基本系统和配置所需基础设施的需要. 然而,这种便利带来了更大的代价.
企业可以通过云提供商和云原生的协同作用,有效地采用大数据系统, open-source tools. 这种组合使他们能够以传统复杂性水平的一小部分构建有能力的后端. 业界现在有了可接受的开源PaaS选项,不再受供应商的限制.
在本文的其余部分中, 我们展示了一个展示ksqlDB和Kubernetes操作符的大数据架构, 哪些依赖于开源 Kafka and Kubernetes (K8s)技术. 此外,我们将合并 YugabyteDB 提供新的可伸缩性和一致性功能. 这些系统中的每一个都很强大,但当它们结合在一起时,它们的能力就会增强. 将我们的组件连接在一起并方便地提供我们的系统,我们依赖于 Pulumi 基础设施即代码(IaC)系统.
我们的样例项目的体系结构需求
让我们定义一个系统的假设需求,以演示针对通用应用程序的大数据架构. 假设我们在当地一家视频流媒体公司工作. On our platform, 我们提供本地化的原创内容, 并且需要跟踪客户观看的每个视频的进度功能.
我们的主要用例是:
Stakeholder
Use Case
Customers
客户内容消费生成系统事件.
第三方许可证持有人
第三方许可证持有者根据自己的内容消费获得版税.
集成的广告商
广告商需要基于用户行为的印象度量报告.
假设我们每天有20万用户,同时有10万用户的峰值负载. 每个用户每天看两个小时的手表,我们希望以五秒的精度跟踪进度. 数据不需要很高的准确性(例如,与支付系统相比)。.
所以我们大概有3亿 heartbeat events 每天,在高峰时间每秒100,000个请求(RPS);
300,000 users x 1,440 每用户每天2小时以上产生的心跳事件(每分钟12次心跳事件×每天120分钟) = 288,000,000 heartbeats per day ≅ 300,000,000
我们可以使用简单可靠的子系统,比如RabbitMQ和SQL Server, 但是我们的系统负载数超过了这些子系统能力的极限. 如果我们的业务和交易负载增长100%, for instance, 这些单个服务器将不再能够处理工作负载. 我们需要水平扩展的存储和处理系统, 作为开发人员,我们必须使用有能力的工具——否则后果自负.
在我们选择特定的系统之前,让我们考虑一下我们的高层架构:
总体与云无关的系统架构
指定了系统结构后,我们现在开始寻找合适的系统.
Data Storage
大数据需要数据库. 我注意到一种趋势,从纯关系模式转向SQL和NoSQL方法的混合.
SQL和NoSQL数据库
为什么公司选择每一种类型的数据库?
SQL
NoSQL
支持面向事务的系统,如会计或财务应用程序.
要求高度的数据完整性和安全性.
支持动态模式.
允许水平扩展.
通过简单的查询提供出色的性能.
每种类型的现代数据库都开始实现彼此的特征. SQL和NoSQL产品之间的差异正在迅速缩小, 这使得为我们的架构选择工具变得更具挑战性. Current database industry rankings 表明有近400个数据库可供选择.
分布式SQL数据库
Interestingly, 一类新的数据库已经发展到涵盖NoSQL和SQL系统的所有重要功能. 这个新兴类的一个显著特征是,它是物理上分布在多个节点上的单个逻辑SQL数据库. 虽然不提供动态模式,但新的数据库类拥有以下关键特性:
Transactions
同步复制
Query distribution
分布式数据存储
水平写可伸缩性
根据我们的要求,我们的设计应该避免云锁定,消除数据库服务,如 Amazon Aurora or Google Spanner. 我们的设计还应该确保分布式数据库能够处理预期的数据量. 我们将使用高性能和开源 YugabyteDB用于我们的项目需要 ; here’s what the resulting cluster architecture will look like:
一个假想的YugabyteDB分布式数据库及其流量控制器
更准确地说,我们选择YugabyteDB是因为它是:
PostgreSQL兼容,并与许多PostgreSQL数据库工具(如语言驱动程序)一起工作, 对象关系映射(ORM)工具, 以及模式迁移工具.
水平扩展,性能随着节点的增加而扩展.
数据层具有弹性和一致性.
可部署在公共云中,本机使用Kubernetes,或在其自己的托管服务上.
100%开源,具有强大的企业功能,如分布式备份, 静态数据加密, in-flight TLS encryption 、更改数据捕获和读取副本.
我们选择的产品还具有任何开源项目所需的属性:
With YugabyteDB, 我们有一个完美的匹配我们的建筑, 现在我们来看看我们的流处理引擎.
实时流处理
您应该记得,我们的示例项目每天有3亿个心跳事件,结果是100,每秒000个请求. 这种吞吐量产生了大量原始形式的数据,这些数据对我们没有用处. We can, however, 将其聚合以合成我们想要的最终形式, 他们看了哪些视频片段?
使用这种表单可以大大减少数据存储需求. 将原始数据转换为所需格式, 我们必须首先实现实时流处理基础设施.
许多没有大数据经验的小型团队可能会通过实现订阅消息代理的微服务来实现这种转换, 从数据库中选择最近的事件, 然后将处理过的数据发布到另一个队列. 虽然这个方法很简单, 它迫使团队处理重复数据删除, reconnections, ORMs, secrets management, testing, and deployment.
更有经验的流处理团队倾向于选择更昂贵的AWS Kinesis或更实惠的Apache Spark Structured Streaming. Apache Spark是开源的,但是是特定于供应商的. 因为我们架构的目标是使用开源组件,这使我们能够灵活地选择托管合作伙伴, 我们来看看第三个, 有趣的选择:Kafka与 Confluent 的开源产品包括 schema registry , Kafka Connect , and ksqlDB.
Kafka本身就是一个分布式日志系统. 传统的Kafka商店使用Kafka Streams来实现他们的流处理, 但我们将使用sqldb, 一个更高级的工具,包含Kafka流的功能:
ksqlDB倒金字塔
More specifically, ksqlDB —a server, 不是库,是一个流处理引擎,它允许我们用类似sql的语言编写处理查询. 我们所有的函数都运行在一个ksqlDB集群中, typically, 我们的物理位置靠近Kafka集群, 从而最大化我们的数据吞吐量和处理性能.
我们将把处理的所有数据存储在外部数据库中. Kafka Connect 允许我们通过作为一个框架来连接Kafka与其他数据库和外部系统来轻松地做到这一点, 比如键值存储, search indices, and file systems. 如果我们想导入或导出一个主题——Kafka术语中的“流”——到数据库中, 我们不需要编写任何代码.
Together, 这些组件允许我们摄取和处理数据(例如, 将心跳分组到窗口会话中,并保存到数据库中,而无需编写我们自己的传统服务. 我们的系统可以处理任何工作负载,因为它是分布式和可扩展的.
卡夫卡并不完美. 它很复杂,需要深厚的知识来设置、使用和维护. 因为我们没有维护自己的生产基础设施, 我们将使用Confluent的托管服务. At the same time, Kafka有一个庞大的社区和大量的样本和文档,可以帮助我们在任何情况下.
现在我们已经介绍了核心体系结构组件, 让我们看看操作工具,让我们的生活更简单.
Infrastructure-as-code: Pulumi
基础设施即代码(IaC)使DevOps团队能够使用简单的指令在多个提供商之间大规模地部署和管理基础设施. IaC是任何云开发项目的关键最佳实践.
大多数使用IaC的团队倾向于使用Terraform或像AWS CDK这样的云原生产品. Terraform要求我们使用其产品特有的语言进行编写, AWS CDK只在AWS生态系统内工作. 我们更喜欢这样一种工具,它在编写部署规范时具有更好的灵活性,并且不会将我们锁定在特定的供应商中. Pulumi完全符合这些要求.
Pulumi是一个云原生平台,允许我们部署任何云基础设施, 包括虚拟服务器, containers, applications, 无服务器功能.
我们不需要学习一门新的语言来和Pulumi合作. 我们可以用我们最喜欢的一个:
Python
JavaScript
TypeScript
Go
.NET/C#
Java
YAML
TypeScript中的Pulumi定义示例
那么我们如何让Pulumi发挥作用? 例如,假设我们想在AWS中配置一个EKS集群. We would:
Install Pulumi .
安装和配置 AWS CLI .
Pulumi只是一个受支持的提供者之上的智能包装器.
一些提供程序需要调用它们的HTTP API,而另一些,比如AWS,则依赖于它的CLI.
Run pulumi up.
Pulumi引擎从存储器中读取其当前状态, 计算对代码所做的更改, 并尝试应用这些变化.
在理想情况下,我们的基础设施将通过IaC进行安装和配置. 我们将把整个基础设施描述存储在Git中, write unit tests, use pull requests, 并在我们的持续集成和持续部署工具中使用一键创建整个环境.
Kubernetes运营商
Kubernetes是一个云应用程序操作系统. 它可以是自我管理的、被管理的、裸机的,也可以在云中、K3s或OpenShift中. 但核心始终是Kubernetes. 除了涉及无服务器的罕见实例之外, legacy, 以及特定于供应商的系统, 在构建可靠的体系结构时,Kubernetes是必备的组件, 而且越来越受欢迎.
比较Kubernetes谷歌搜索趋势
我们将把所有有状态和无状态的服务部署到Kubernetes. 对于我们的有状态服务(i.e.(YugabyteDB和Kafka),我们将使用额外的子系统:Kubernetes操作符.
Kubernetes操作员控制回路
Kubernetes操作符是在Kubernetes中运行和管理其他资源的程序. 例如,如果我们想安装一个Kafka集群及其所有组件(e.g., schema registry, Kafka Connect), 我们需要监督数百种资源, 例如有状态集, services, PVCs, volumes, config maps, and secrets. Kubernetes操作符通过消除管理这些服务的开销来帮助我们.
有状态系统发布者和企业开发人员是这些操作符的主要作者. 常规的开发人员和IT团队可以利用这些操作来更轻松地管理他们的基础设施. 操作人员允许直接, 声明性状态定义,然后用于供应, configure, update, 并管理他们的相关系统.
在早期的大数据时代, 开发人员使用原始清单定义管理他们的Kubernetes集群. Then Helm 进入画面并简化了Kubernetes操作, 但仍有进一步优化的空间. Kubernetes操作符应运而生, 与赫尔姆一致, 使Kubernetes成为开发人员可以快速付诸实践的技术.
来证明这些操作符是多么的普遍, 我们可以看到,本文中介绍的每个系统都有其发布的操作符:
Pulumi
Uses an operator 实现GitOps原则,并在提交到git存储库后立即应用更改.
Kafka
对于它的所有组件,有两个操作符:
YugabyteDB
Provides an operator for ease of use.
在讨论了所有重要的组件之后,我们现在可以检查我们系统的概述.
我们的架构与首选系统
虽然我们的设计包含许多组件, 我们的系统在整体架构图中相对简单:
整体云专用架构
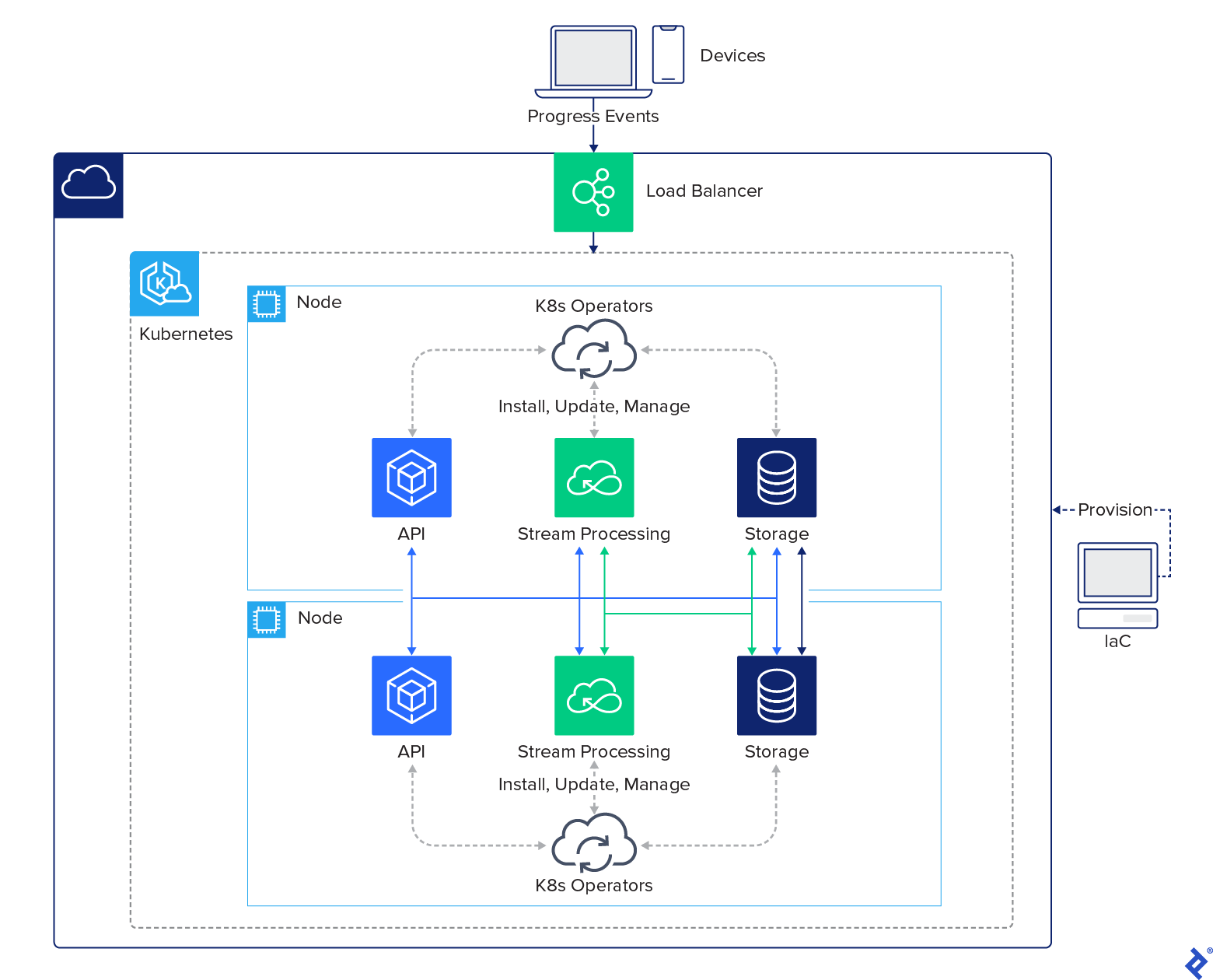
关注我们的Kubernetes环境, 我们可以简单地安装Kubernetes操作符, Strimzi和YugabyteDB, 他们将完成其余的工作来安装剩下的服务. Kubernetes环境中的整体生态系统如下:
Kubernetes环境
此部署描述了使用当今技术简化的分布式云架构. 实现五年前不可能实现的事情,今天可能只需要几个小时.
Toptal工程博客的编辑团队向 David Prifti and Deepak Agrawal 查看本文中提供的技术内容和代码示例.










 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.